LinkedList从字面上看就是一个链表,它的底层是使用的双链表结构实现的
开场
- 值是否可以重复 -> 可以
- 值是否可以为null -> 可以
- 值是否有序 -> 按照插入顺序排列
- 是否是线程安全 -> 否
LinkedList的总体结构
类定义
1 | |
重要的参数
1 | |
双链表的结构
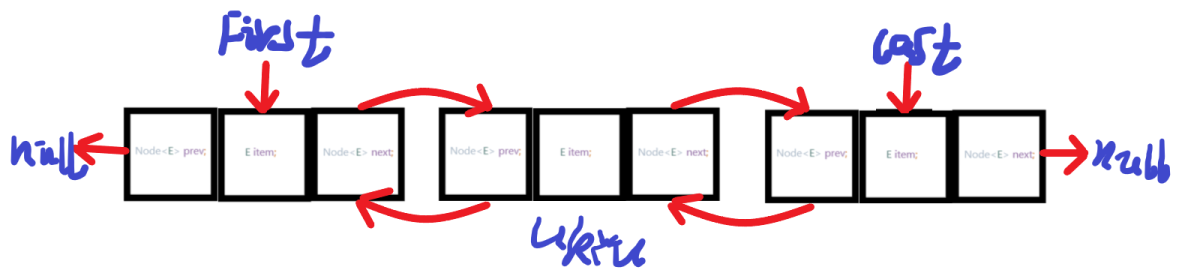
方法的剖析
讲一些重要的地方,都是基于对双链表的操作,看看源代码就可以懂得
- add方法
1 | |
- 获取特定索引的非空节点(node方法)
1 | |
- 获取值
1 | |
-
获取头节点与尾节点
1
2LinkedList提供给了多种获取last与first的方法 具体区别可以查看源码,做个小小的了解.
与ArrayList的区别
其实最关心的也是这两者的区别
写在前面
ArrayList的类定义
1 | |
ArrayList实现了RandomAccess接口
RandomAccess接口
Marker interface used by List implementations to indicate that they support fast (generally constant time) random access. (实现了该接口的list,表明他们支持快速的随机访问),The primary purpose of this interface is to allow generic algorithms to alter their behavior to provide good performance when applied to either random or sequential access lists.(提供更好的性能在随机访问或顺序访问的时候)
随机与顺序访问
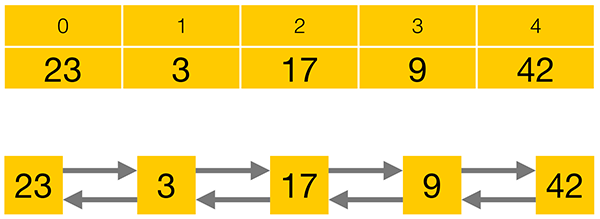
当我想要9, 第一张图,可以直接访问index = 3的元素,而第二张图,只能通过23->3->17->9或者42->9的方式,这就是随机与顺序访问的区别
区别
ArrayList、LinkedList
- 前者支持随机访问,而后者只支持顺序访问。
- 前者花费的时间主要是数组扩容上,后者花费的时间主要在于根据索引顺序访问和新建节点(Node)上
- 后者的每个节点要保存前后节点的信息,若对象较大的话,占的内存会较多
一般认识都是,前者访问快,后者 (在last节点、first节点) 增删较快
若性能需要优化,试试在具体的业务场景中,使用性能测试,记住两者在什么操作上耗时较多即可.
需注意
后者使用get(index)循环时,耗时非常大(大量数据), 上文也讲述了原因,可以根据不同类型的列表使用不同的遍历方式
1 | |
学到了什么
- LinkedList底层主要对双链表进行操作
- 实现RandomAccess接口的list,表明该list支持快速随机访问
- 实现了RandomAccess的列表,可以使用任何方式遍历,没有实现的就使用迭代的方式进行遍历
对自己的现状不满意只有付出更多的努力去改变它
如果有不对的地方或建议,请指出,谢谢啦